Radmap
Online woordenboek en etymologische visualisatie van Chinese karakters


Over Radmap
Radmap is a cross-over between a visualization and dictionary for the Chinese language. The project was developed at the Jan Van Eyck Academy in Maastricht as a result of a 2 year research about Chinese language and digital visualization.
Animation
An amination shows the 6743 most common Chinese characters being added to a bar chart, one by one. 186 bars, each representing a Chinese radical. These radicals are used to categorize characters, for example in dictionaries. The sequence starts with the most common character and ends with the least used. One at a time, characters 'fall' on to their radical(s) in the chart, making the bars grow.

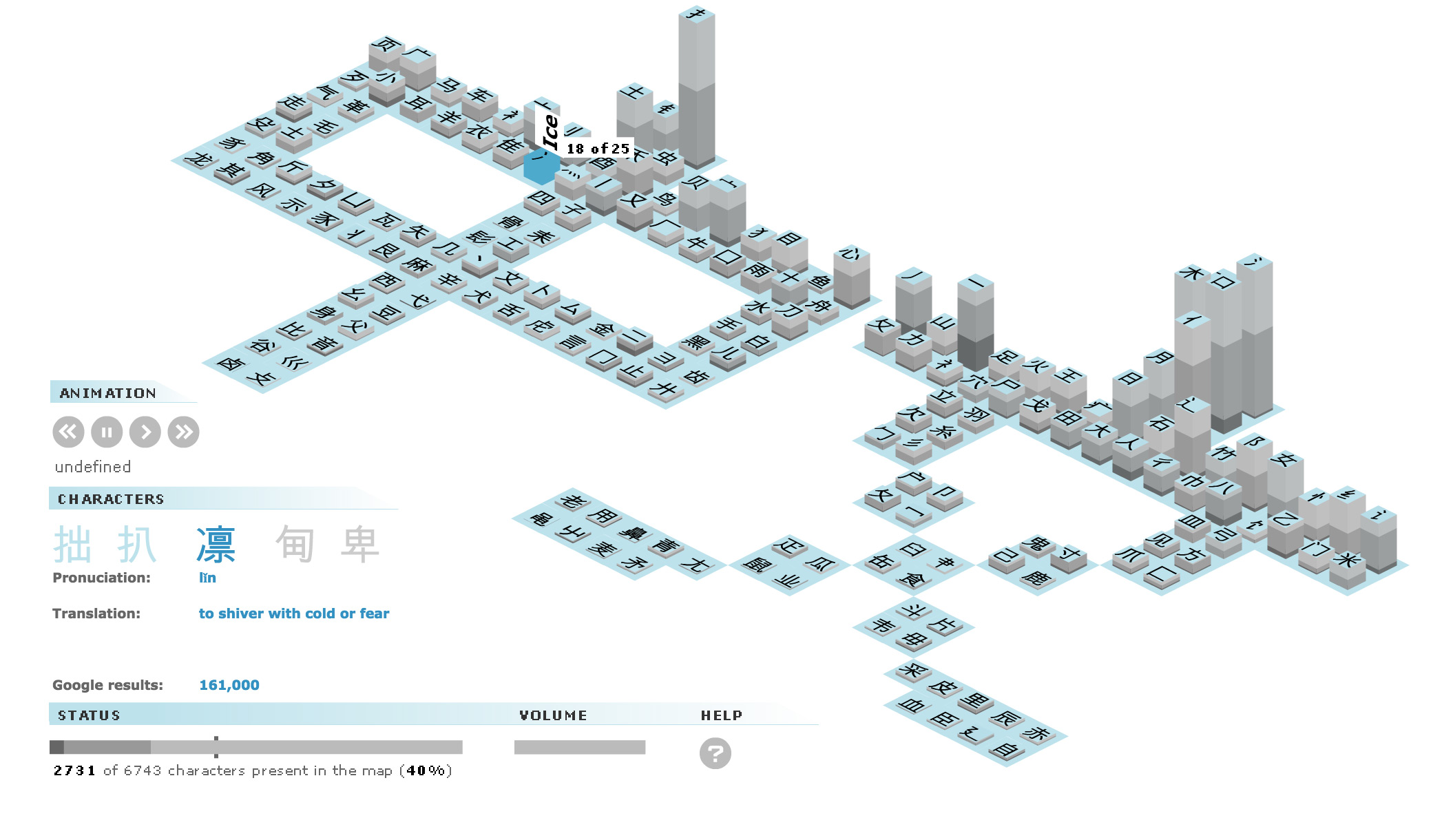
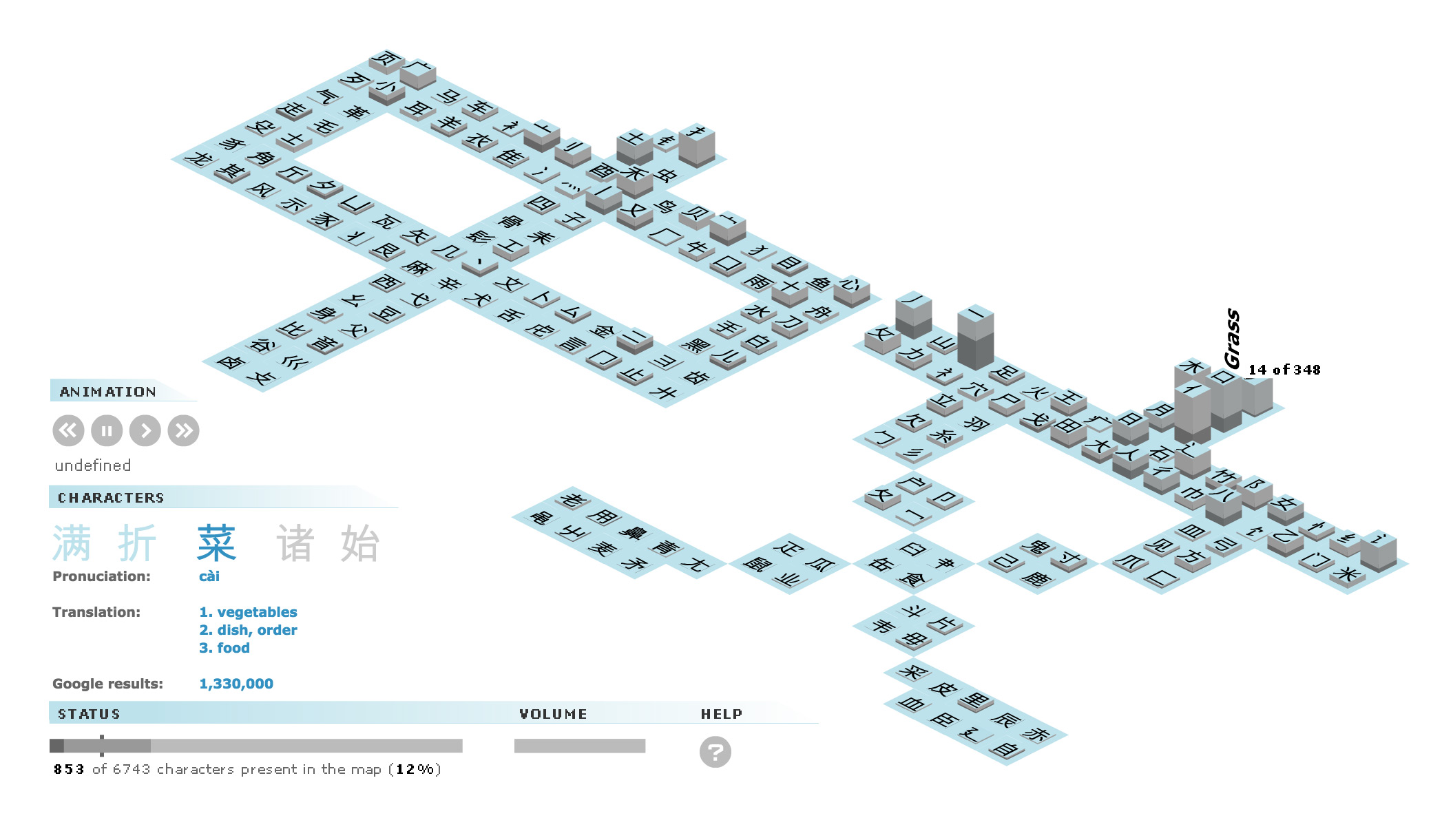

Etymological dictionary
Clicking on a bar shows all the characters belonging to that radical, together with the radical's etymology and character's translations and pronunciations.
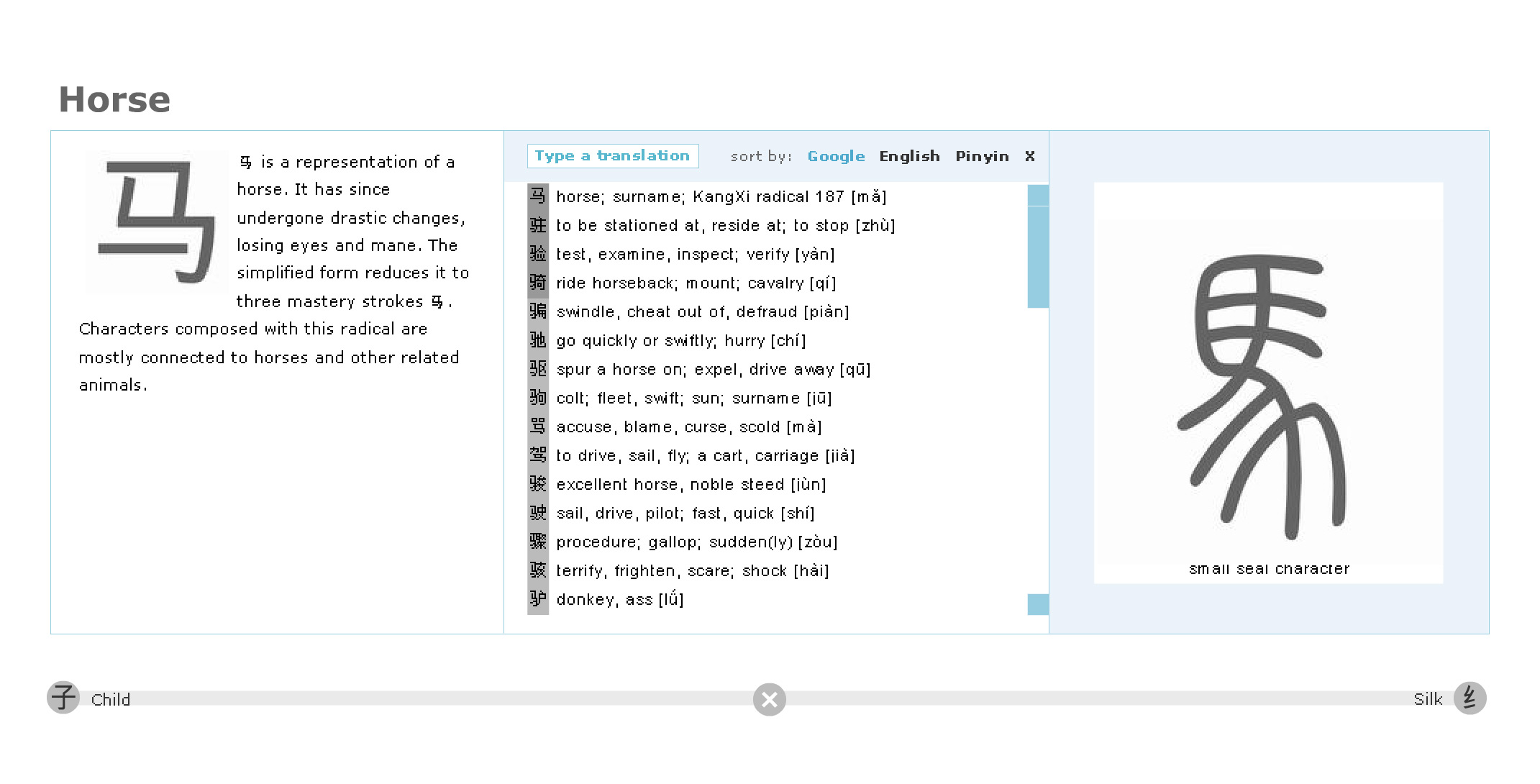

More information
https://rekall.be/_private_projects/radmap/radmap_flash.htm
OBJECTIVES
The project focuses on the development of an online Chinese language dictionary. The aim of the research is to create more sophisticated front-end interfaces that enable visualizations of relations and connections between different words (Chinese characters), instead of simply following the 'search and find' approach. Our goal is to amplify and deepen the user's understanding of Chinese language.
IMPORTANT NOTES
Most of the data is freely available from the sources mentioned below. None of this information has been proofed, so might or might not be reliable.
The 'frequency of usage' is measured as the number of results returned by a Google search. This means that characters typically found in spoken language are under-represented, whereas characters specific for written language and business and computers will be over-represented.
SOURCES FOR THE DATA
- list of characters — almost identical to the Chinese characters in GB 2312-80, which is the most common character set for Chinese web pages.
- radicals — adapted from the list by Ngai Kim Hoong.
- frequency of usage — obtained by passing every character to a Perl script returning the number of search results. Uses the Google web api.
- translations — obtained from the Unihan database using the Unicode::Unihan perl module by Dan Kogai (and the data for those two Unihan fields is taken from the CEDICT).
- pinyin — obtained from the zidianf file by Adrian Robert.
- sounds files for the pinyin — adapted from .wav files from an unknown source.
This project was supported by the Jan van Eyck Academie, Maastricht, NL.
Voor dit project waren wij verantwoordelijk voor: informatie architectuur, design, frontend, programmatie.